
Authors
Wufei Ma*, Qihao Liu*, Jiahao Wang*, Xiaoding Yuan, Angtian Wang, Yi Zhang, Zihao Xiao, Guofeng Zhang, Beijia Lu, Ruxiao Duan, Yongrui Qi, Adam Kortylewski, Yaoyao Liu✉, Alan Yuille
Affiliations
Johns Hopkins University, University of Freiburg, Max Planck Institute for Informatics
We present 3D Diffusion Style Transfer (3D-DST), a simple and effective approach to incorporate 3D geometry control into diffusion models. Our method exploits ControlNet, which extends diffusion models by using visual prompts in addition to text prompts. We generate images of the 3D objects taken from 3D shape repositories, e.g., ShapeNet and Objaverse, render them from a variety of poses and viewing directions, compute the edge maps of the rendered images, and use these edge maps as visual prompts to generate realistic images. With explicit 3D geometry control, we can easily change the 3D structures of the objects in the generated images and obtain ground-truth 3D annotations automatically.
- Widely applicable. The simple formulation of our framework allows us to apply our method to a wide range of vision tasks, e.g., image classification, 3D pose estimation, and 3D object detection.
- Improved robustness. With our diverse prompt generation, we achieve a higher level of realism and diversity. Models pretrained on our 3D-DST achieves improved robustness when tested on OOD datasets.
- Removing biases. With explicit 3D control, our 3D-DST data are not subject to 3D biases inherent in other synthetic datasets generated by 2D diffusion models.
Framework
Our 3D-DST comprises three essential steps:
- 3D visual prompt generation. We generate images of 3D objects taken from a 3D shape repository (e.g., ShapeNet and Objaverse), render them from a variety of viewpoints and distances, compute the edge maps of the rendered images, and use these edge maps as 3D visual prompts.
- Text prompt generation. Our approach involves combining the class names of objects with the associated tags or keywords of the CAD models. This combined information forms the initial text prompts. Then, we enhance these prompts by incorporating the descriptions generated by LLaMA.
- Image generation. We generate photo-realistic images with 3D visual and text prompts using Stable Diffusion and ControlNet.
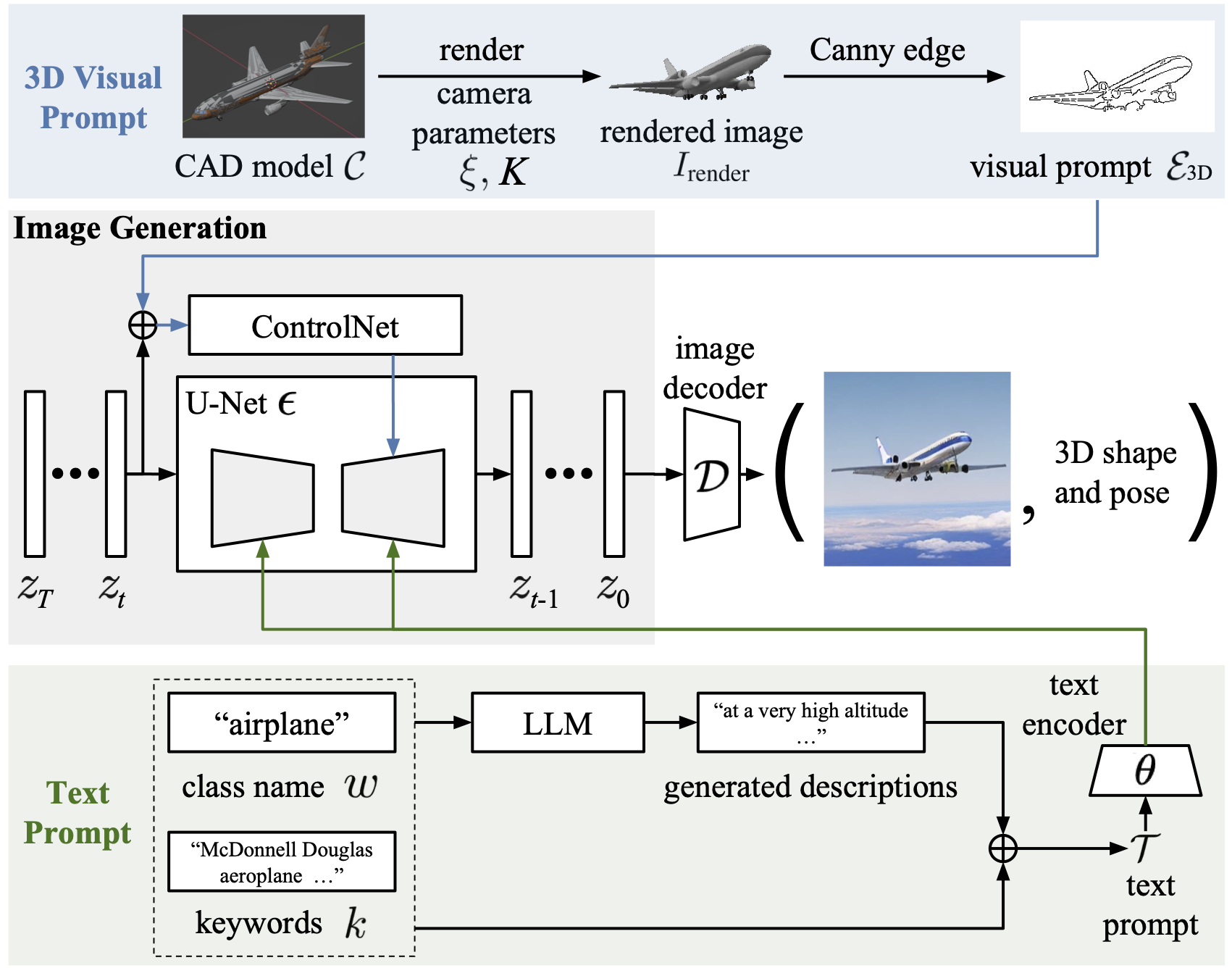
Prompt Generation
We present a novel strategy for text prompt generation. We form the initial text prompt by combining the class names of objects with the associated tags or keywords of the CAD models. This helps to specify fine-grained information that are not available in standard class prompts, e.g., subtypes of vehicles beyond "An image of a car". Then we improve the diversity and richness of the text prompts by utilizing the text completion capabilities of LLMs.
Results show that our method not only produces images with higher realism and diversity but also effectively improve the OOD robustness of models pretrained on our 3D-DST data.

Main Results
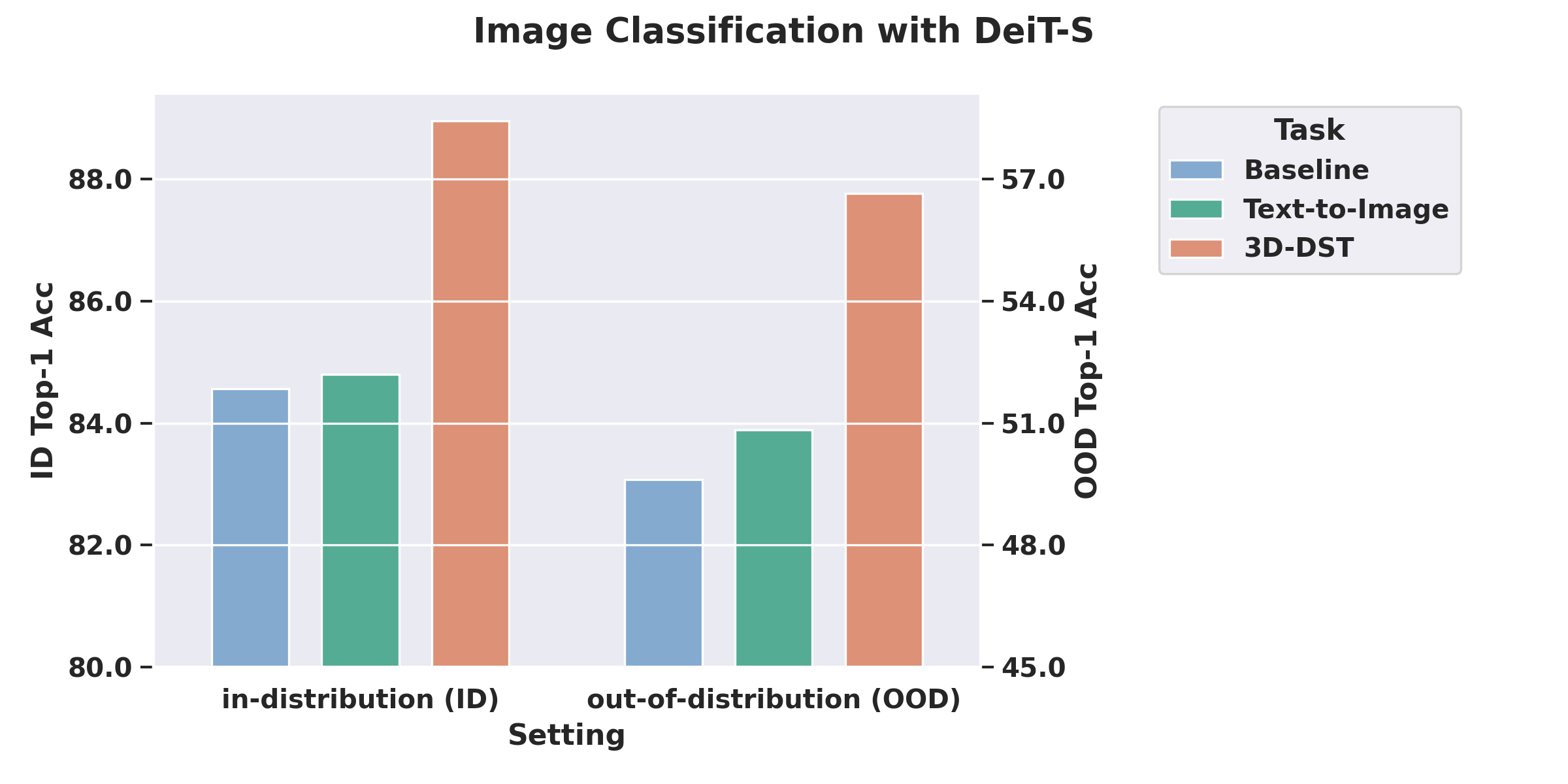
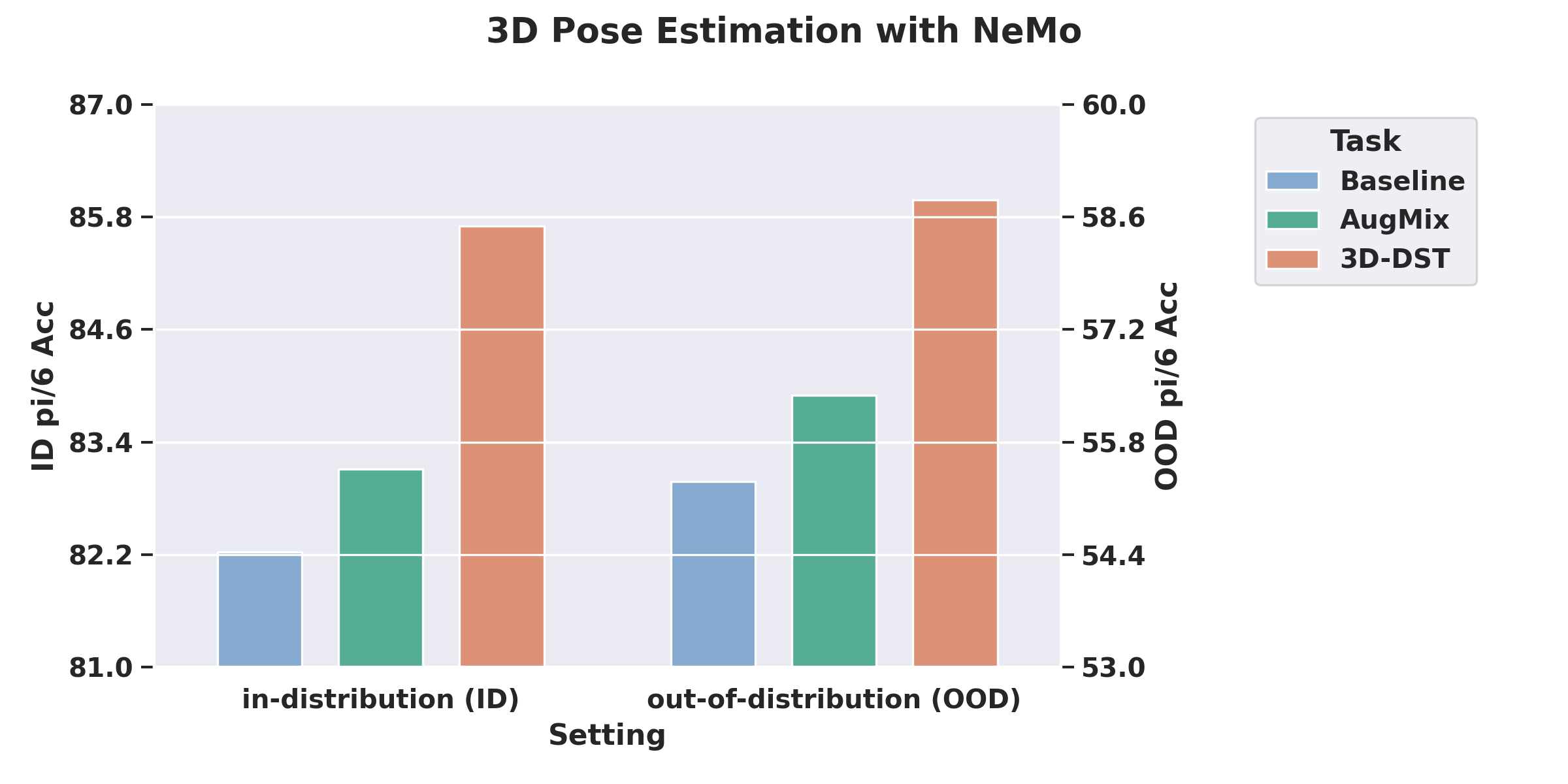
We show that models pretrained on our 3D-DST data achieves improvements on both ID and OOD test set for image classification (on ImageNet-100 and ImageNet-R) and 3D pose estimation (on PASCAL3D+ and OOD-CV).
Analyses of Failure Cases
We collect feedback from human evaluators on the quality of our 3D-DST images and carefully analyze the failure cases of our generation pipeline. We identify a limitation of our model to be images with challenging and uncommon viewpoints (e.g., looking at cars from below or guitars from the side).
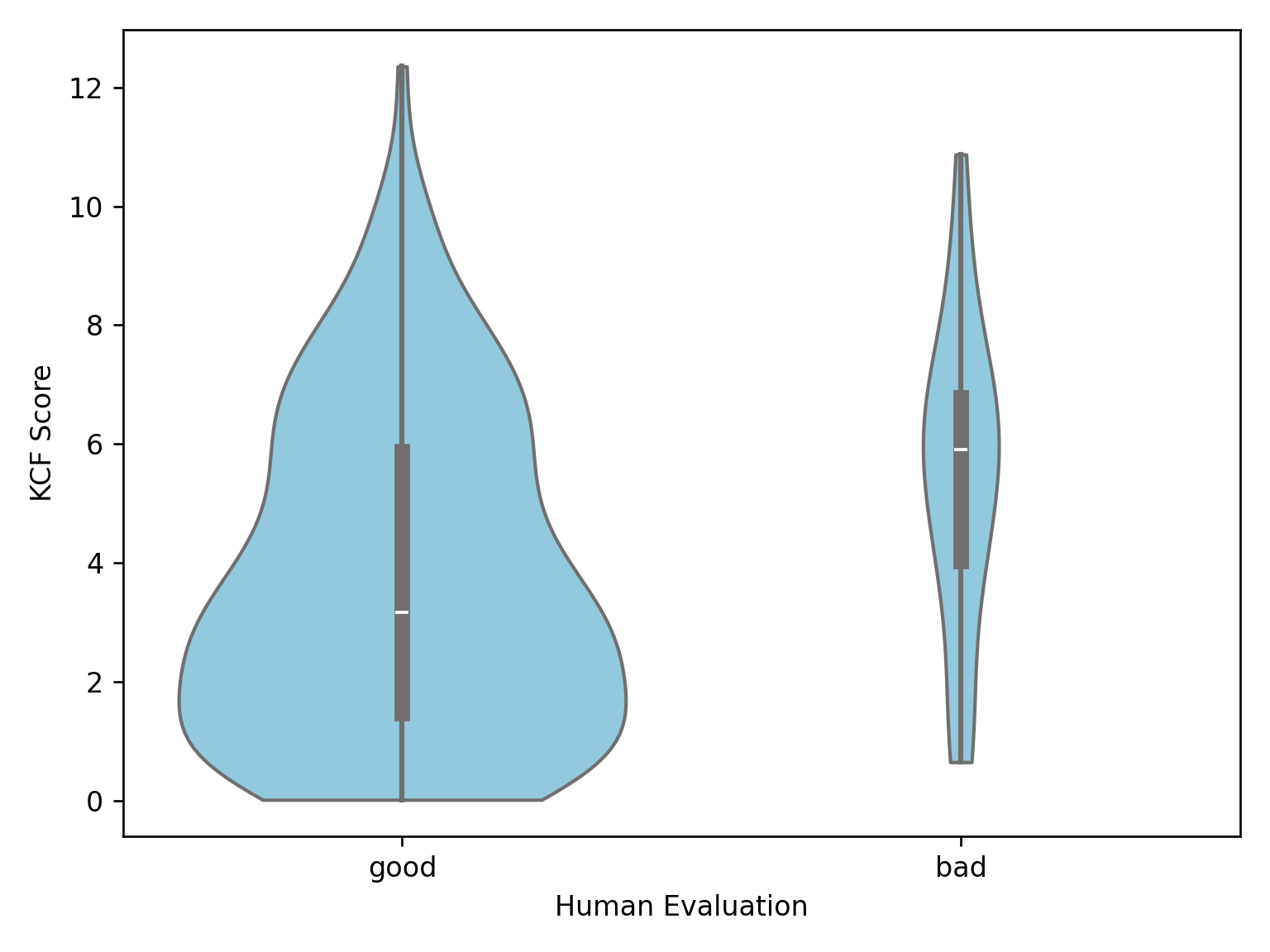
We further develop a K-fold consistency filter (KCF) to automatically remove failed images based on the predictions of an ensemble model. We find that KCF improves the ratio of correct samples, despite falsely removing a certain amount of good images.
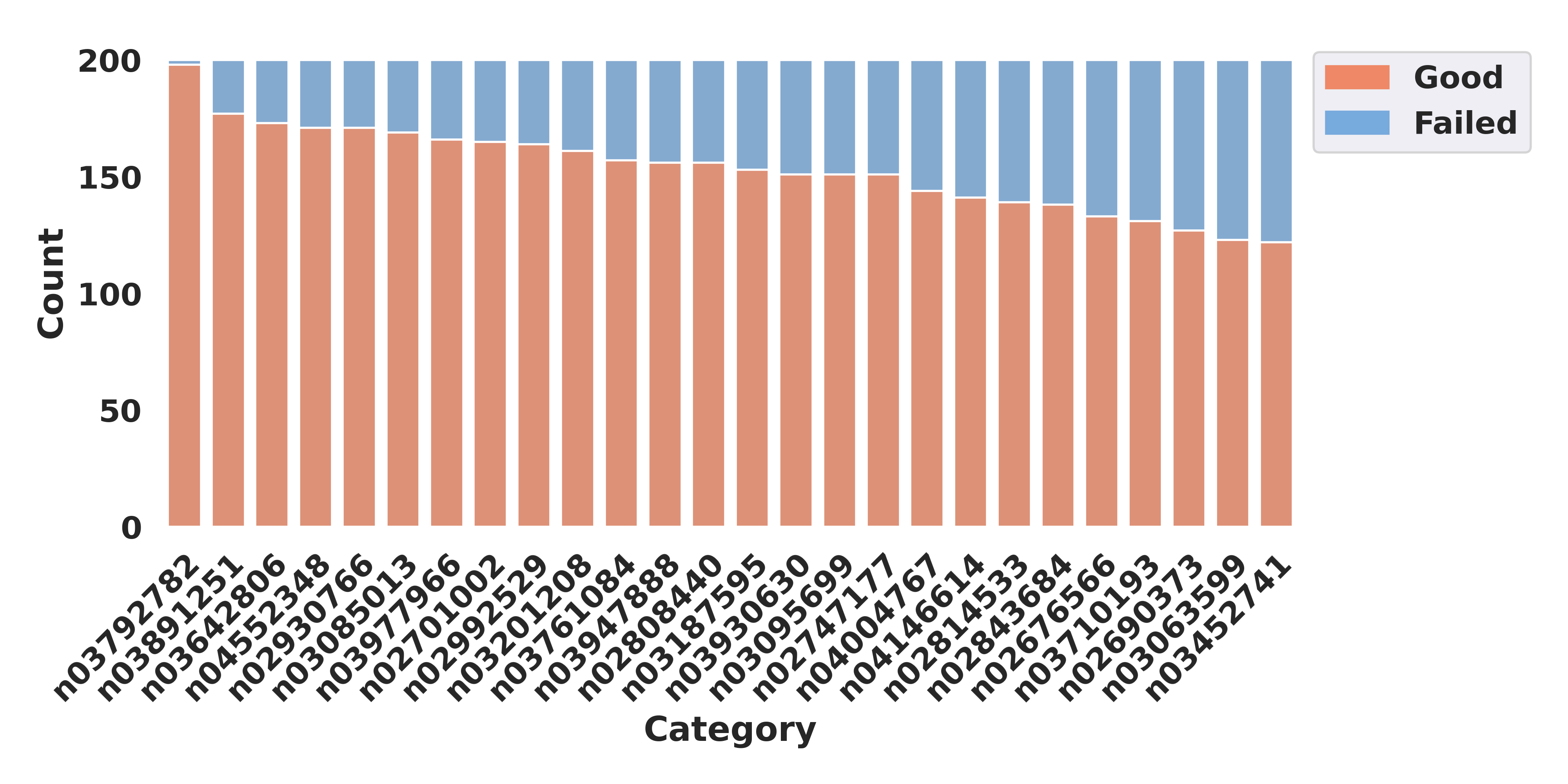
K-Fold Consistency Filter (KCF)
We further develop a K-fold consistency filter (KCF) to automatically remove failed images based on the predictions of an ensemble model. We find that KCF improves the ratio of correct samples, despite falsely removing a certain amount of good images.
Here we present some preliminary results showing that KCF can improve the ratio of good images by around 5%. Our KCF serves as a proof-of-concept to remove synthetic images with inconsistent 3D formulations. KCF is still limited in many ways and we note that detecting and removing failed samples in diffusion-generated datasets is still a challenging problem.
Data Release
Besides code to reproduce our data generation pipeline, we also release the following data to support other research projects in the community:
- Aligned CAD models for all 1000 classes in ImageNet-1k. For each ImageNet-1k class, we collect CAD models from ShapeNet, Objaverse, and OmniObject3D, and align the canonical poses of the CAD models. These CAD models can be used to produce diverse synthetic data for various 3D tasks. See ccvl/3D-DST-models.
- LLM-generated captions for all 1000 classes in ImageNet-1k. These captions can be used to reproduce our 3D-DST data or to generate other synthetic datasets for fair comparisons between different data generation procedures. See ccvl/3D-DST-captions.
- 3D-DST data for all 1000 classes in ImageNet-1k. (Coming soon...)
Team













* denotes equal contribution
✉ corresponding author



BibTeX
@inproceedings{ma2024generating,
title={Generating Images with 3D Annotations Using Diffusion Models},
author={Wufei Ma and Qihao Liu and Jiahao Wang and Angtian Wang and Xiaoding Yuan and Yi Zhang and Zihao Xiao and Guofeng Zhang and Beijia Lu and Ruxiao Duan and Yongrui Qi and Adam Kortylewski and Yaoyao Liu and Alan Yuille},
booktitle={The Twelfth International Conference on Learning Representations},
year={2024},
url={https://openreview.net/forum?id=XlkN11Xj6J}
}